A record of my notes and learnings from a course i’m currently undertaking called ’AI Safety Technical Fundamentals - AI Alignment’ by BlueDot Impact.
Week 1: Artificial General Intelligence
Learning Goals
- Define what ‘foundation models’ are and understand how they are trained.
- Describe the current state of the art in machine learning, and summarise the rate of progress.
- Propose the capability requirements for an AI system to be defined as AGI.
- Contrast modern machine learning with your blueprint for AGI, and evaluate if/when AGI could be developed.
- Evaluate the likelihood that a transition from modern ML to AGI leads to qualitatively different behaviour.
Summary:
Foundation Models
- Emergence: behaviour of the systems is implicitly induced vs. explicitly constructed.
- Homogenization: the consolidation of metholodies for building ML systems across general applications. The process of making different things the same, or at least more similar. It suggests a convergence towards a common standard or approach.
- (ML homogenizes learning algorithms => logistic regression; DL hom model architectures => CNN; foundation models homogenize the model itself => GPT-3)
- when we say foundation models homogenize themselves we mean: the foundation model standardizes the core architecture and functionalities that are used across a wide range of applications and tasks. Foundation models like GPT-3 use a singular, unified architecture (in this case, the Transformer architecture) that can handle a variety of tasks that previously would have required multiple specialized architectures.
- (ML homogenizes learning algorithms => logistic regression; DL hom model architectures => CNN; foundation models homogenize the model itself => GPT-3)
Week 2: Reward misspecification and instrumental convergence
Explain how reward functions can fall short of specifying our intentions.
- Understand what a reward function is and why they're used.
- Define the terms 'reward misspecification' and 'reward hacking'.
- Examine whether reward hacking could play a part in catastrophic failure in advanced systems.
A reward function is a type of task specification.
reward misspecification: where the default techniques for training ML models often unintentionally assign high rewards to undesirable behaviour. reward hacking is behaviour that exploits reward misspecification to get a high reward.
- why does it happen: due to failure to capture our exact desires for the resulting systems’ behaviour in the reward function or loss function that we use to train machine learning systems.
specification gaming is behaviour that meets the literal specification of the objective as written/programmed without achieving the actual intended outcome (as imagined by the programmer). E.g. specify goal as use robotic arm to move block to the target spot on the table; actual action: agent moves table so that target spot falls under the block.
In the real world specification gaming is problematic, as it involves the agent exploiting a loophole in the specification at the expense of the intended outcome.
These behaviours are caused by misspecification of the intended task, rather than any flaw in the RL algorithm. Set the parameters wisely!
- why is it so hard: Even for a slight misspecification, a very good RL algorithm might be able to find an intricate solution that is quite different from the intended solution, even if a poorer algorithm would not be able to find this solution. As RL algorithms get better and better, correctly specifying intent will become more important than ever.
task specification are the many facets of the agent development process. These include: reward design, the choice of training environment and auxilary rewards.
if done right: If the specification is right, the RL agent’s powerful creativity produces a desirable novel solution.
causes of specification gaming:
- reward shaping: Reward shaping makes it easier to learn some objectives by giving the agent some rewards on the way to solving a task, instead of only rewarding the final outcome.
approaches to address specification gaming:
- learning the reward function from human feedback vs. granular specification
- good specifications
reward tampering: Any task specification has a physical manifestation: a reward function stored on a computer, or preferences stored in the head of a human. An agent deployed in the real world can potentially manipulate these representations of the objective
- there is no clear distinction between satisfying the user’s preferences (e.g. by giving useful directions), and influencing users to have preferences that are easier to satisfy (e.g. by nudging them to choose destinations that are easier to reach).*
Aligned RL Agent Design =
Good RL Algorithm Design (agents achieve high reward) +
Good Reward Design (reward function that capture intended outcomes) +
Avoidance of Reward Tampering (removal of incentives to tamper)
Explain what RLHF is and why it is proposed as a way to help deal with reward misspecification.
Predict ways in which RLHF could lead to undesirable outcomes, given an arbitrary environment and task.
What is RLHF? In general, the human decides which of two actions the agent does is closest to fulfilling its goal— e.g. a backflip. The AI gradually builds a model of the goal of the task by finding the reward function that best explains the human’s judgments. It then uses RL to learn how to achieve that goal. As its behaviour improves, it continues to ask for human feedback on trajectory pairs where it’s most uncertain about which is better, and further refines its understanding of the goal.
- Agent: Complete random actions
- Human: provide feedback on which actions are more correct
- Agent: Builds model of the implied goal by finding the right reward function that best explains the human’s judgement.
- Agent: Use RL to learn to achieve the goal
- Human: Provide more feedback as required
- Agent: Reduce uncertainty with more feedback, refine understanding of the goal.
Learning to summarise with human feedback Our core method consists of four steps: training an initial summarization model, assembling a dataset of human comparisons between summaries, training a reward model to predict the human-preferred summary, and then fine-tuning our summarization models with RL to get a high reward.
- Train a GPT-style model on a main dataset and then fine tune for specific purpose via supervised learning. E.g. model creates human tl;dr for reddit posts
- Collect a dataset of human-quality judgement of posts summarised by the model. For each judgment, a human compares two summaries of a given post and picks the one they think is better. The specific choices of the humans labelling the data has an outsized impact on the quality of the trained models.
- this data to train a reward model that maps a (post, summary) pair to a reward r. The reward model is trained to predict which summary a human will prefer, using the rewards as logits.
- Finally, we optimize the policy against the reward model using RL.
Deciding what makes a good summary is fairly straightforward, but doing this for tasks with more complex objectives, where different humans might disagree on the correct model behavior, will require significant care. In these cases, it is likely not appropriate to use researcher labels as the “gold standard”; rather, individuals from groups that will be impacted by the technology should be included in the process to define “good” behavior, and hired as labelers to reinforce this behavior in the model.
- i.e. for controversial or contentious topics we need a wider cross section of society to provide human feedback.

The risks of RLHF: RLHF may encourage the emergence of three problematic properties.
- First, human feedback rewards models for appearing harmless and ethical, while also maximizing useful outcomes. The tension between these criteria incentivizes situationally-aware reward hacking (Section 2) where policies ex- ploit human fallibility to gain high reward.
- Second, RLHF-trained AGIs will likely learn to plan towards misaligned internally-represented goals that generalize beyond the RLHF fine-tuning distribution (Section 3).
- Such misaligned AGIs would likely pursue these goals using unwanted power-seeking behaviours such as acquiring resources, proliferating, and avoiding shutdown.
Situational awareness is where models become competent at identifying which abstract knowledge is relevant to the policies themselves and to the context in which they’re being run, and applying that knowledge when choosing actions. Models with high situational awareness would:
- Model how humans will respond to its behavior in a range of situations and which behaviours humans are looking for
- Understand that it is a ML system implemented on physical hardware and hence understand which algorithms and data humans are likely using to train it.
- The interface it is using to interact with the world
GPT-4 is already quite good (85%) at zero-shot accuracy answering challenging questions about situational awareness.
More generally, we should expect that models which are trained on internet text that covers ML models and the contexts in which they are deployed will increasingly learn to use this information when choosing actions, because that would contribute to higher reward on many RL tasks.
situationally-aware reward hacking is a particularly dangerous type of behaviour that makes the prevention of reward hacking much more difficult. Situationally-aware policies could behave as intended most of the time, then choose to exploit mis-specifications only in situations where they predict that it won’t be detected. As models become increasingly complex and outputs increasingly long/complex it may become very difficult to tell whether later policies are actually better-behaved, or have merely learned to reward hack in more subtle ways after being penalized when caught and thereby learning which useful but unwanted behaviours go unnoticed.
Power Seeking: “power” is defined as the ability to achieve a wide range of goals. For example, “money is power,” and money is instrumentally useful for many goals. Conversely, it’s harder to pursue most goals when physically restrained, and so a physically restrained person has little power. An action “seeks power” if it leads to states where the agent has higher power.
An action is instrumental to an objective when it helps achieve that objective. Some actions are instrumental to a range of objectives, making them convergently instrumental. Hence, power-seeking can be thought of a behaviour that is instrumentally convergent.
Understand what IRL is and why it is proposed as a way to help deal with reward misspecification.
Explain why IRL is not typically used to learn human wishes, in modern systems.
In inverse reinforcement learning, we learn a reward function (i.e. what the human values) from observing behavior.
List the proposed instrumental goals, and evaluate to what extent it appears to be a reward misspecification problem.
Instrumental convergence: Several instrumental values can be identified which are convergent in the sense that their attainment would increase the chances of the agent’s goal being realized for a wide range of final goals and a wide range of situations, implying that these instrumental values are likely to be pursued by a broad spectrum of situated intelligent agents.
-
E.g. in Atari games, avoiding (virtual) death is instrumental for both completing the game and for optimizing curiosity
-
the risk: advanced AI agents may have concerning instrumental incentives, such as resisting deactivation and acquiring more resources.
-
Homework:
- A definition of AGI: A system capable of performing at least at average human level on all generalised reasoning tasks even those it is not specifically trained for. And at some reasonable level of competency in real world actions (embodied actions) and the ability to navigate and interact with the world.
- A concrete prediction for expected time for AGI to first emerge, such as the year in which you predict there is a 50% chance that AGI will have emerged by: 2035
Unfamiliar Words
- sample efficiency [Brown et al., 2020, Dorner, 2021]
- cross-task generalization [Adam et al., 2021]
- multi-step reasoning [Chowdhery et al., 2022]
Week 4: Task decomposition for scalable oversight
- Scalable oversight -> approach to preventing reward misspecification
- iterated amplification as a potential solution to scalable oversight -> repeatedly using task decomposition to train increasingly powerful agents.
- task decomposition: the strategy of training agents to perform well on complex tasks by decomposing them into smaller tasks which can be more easily evaluated and then combining those solutions to produce answers to the full task
Scalable oversight
-
the ability to provide reliable supervision—in the form of labels, reward signals, or critiques—to models in a way that will remain effective past the point that models start to achieve broadly human-level performance
-
the techniques here are likely to build on existing techniques used today to steer LLMs (like RLHF) but need to developed further to be effective in regimes where the models have capabilities that we lack and are likely acting intentionally to mislead us.
-
scalable oversight is difficult to pursue right now because:
- current systems differ in many important ways to future system (in ways we may not fully understand yet)
-
sandwiching proposal:
- model is already more capable than a typical human
- model is less capable than an expert
- i.e. sandwiching’ the model’s capabilities between that of the typical humans and the experts
- non-expert humans then attempt to train/align the model to perform the task reliably with an artificial constraint:
- cannot use any help or input (including preexisting materials) from experts
- experts participate at the end, where they evaluate the degree to which non-experts succeeded
-
The sandwiching proposal is a useful analog to what we will face with future AI systems:
- They user has a wide range of tools and techniques at their disposal, including access to an untrustworthy but capable AI system,
- they have no straightforward way to be certain that any of the decisions that they make are correct
-
The hope is that we develop techniques using this paradigm that allow non-experts to effectively align/train models without expert oversight. These techniques can then be carried forward to more capable AI systems.
- for example: prompting a model with a diverse array of prompts and strategies, and accepting only answers that the model gives consistently on the basis of consistent and reasonable-sounding evidence, though this technique is not guaranteed to succeed across the board.
-
The sandwiching experimental design allows us to gain evidence and experience that will allow us to refine techniques like these to better meet the challenges of future more capable AI systems.
-
A full research agenda built around sandwiching will generally have an inner loop and an outer loop
- In the inner loop, the non-experts make iterative attempts to align the model. The loop terminates when they are convinced that the model has been aligned and achieves satisfactory performance. The experts then review the behaviour of the resulting model and evaluate whether it was successfully aligned by comparing its performance with that of a model aligned under their own careful expert supervision.
- The outer loop consists of multiple attempts to develop the scalable oversight strategy and repeat the inner loop. It ends with a verdict on whether any scalable oversight strategy of the type being studied is sufficient to align the model on the task and, if it is not, how often it fails and how harmful its failures are likely to be.
Iterated Amplification
- A technique to specify complicated behaviours and goals that are beyond human scale, by demonstrating how to decompose a task into simpler sub-tasks, rather than by providing labeled data or a reward function
- Training signal - a way to evaluate how well it is doing in order to help it learn (e.g. labels in SL and reward functions in RL)
- If we don’t have a training signal we can’t learn the task, and if we have the wrong training signal, we can get unintended and sometimes dangerous behavior. Thus, it would be valuable for both learning new tasks, and for AI safety, to improve our ability to generate training signals.
- How we generate training signals:
- In some cases, the goal we want can be evaluated algorithmically, like counting up the score in a game of Go or checking whether a set of numbers has been successfully sorted.
- Most real-world tasks don’t lend themselves to an algorithmic training signal, but often we can instead obtain a training signal by:
- However, many tasks are so complicated that a human can’t judge or perform them—examples might be designing a complicated transit system or managing every detail of the security of a large network of computers.
- Iterated amplification is a method for generating a training signal for the latter types of tasks, under certain assumptions:
- although a human can’t perform or judge the whole task directly, we assume that a human can, given a piece of the task, identify clear smaller components of which it’s made up. example: in the networked computer example, a human could break down “defend a collection of servers and routers” into “consider attacks on the servers”, “consider attacks on the routers”, and “consider how the previous two attacks might interact”. Additionally, we assume a human can do very small instances of the task, for example “identify if a specific line in a log file is suspicious”. If these two things hold true, then we can build up a training signal for big tasks from human training signals for small tasks, using the human to coordinate their assembly.
- we start by sampling small subtasks and training the AI system to do them by soliciting demonstrations from humans (who can do these small tasks). We then begin sampling slightly larger tasks, solving them by asking humans to break them up into small pieces, which AI systems trained from the previous step can now solve.
- We use the solutions to these slightly harder tasks, which were obtained with human help, as a training signal to train AI systems to solve these second-level tasks directly (without human help).
- We then continue to further composite tasks, iteratively building up a training signal as we go.
- If the process works, the end result is a totally automated system that can solve highly composite tasks despite starting with no direct training signal for those tasks.
Week 5: Adversarial techniques for scalable oversight
Focus is on two potential alignment techniques proposed to work at scale:
- debate: using AI to critique AI decisions, to help humans give feedback when they can’t gasp the whole task.
- training using unrestricted adversarial examples: using AI to provide oversight during training
Problem: Human struggle at evaluating very difficult tasks (e.g. hard to spot every bug in a large codebase). If human evals are used purely as training signals the AI systems may also give outputs that look good to humans but have errors we fail to notice.
Solution: Train Ai assistants that help humans provide feedback on hard tasks. The assistants should point out flaws, help humans understand what is going on and answer their questions. Example: Book summarisation -> humans assisted with chapter summaries have an easier time evaluating a book summary.
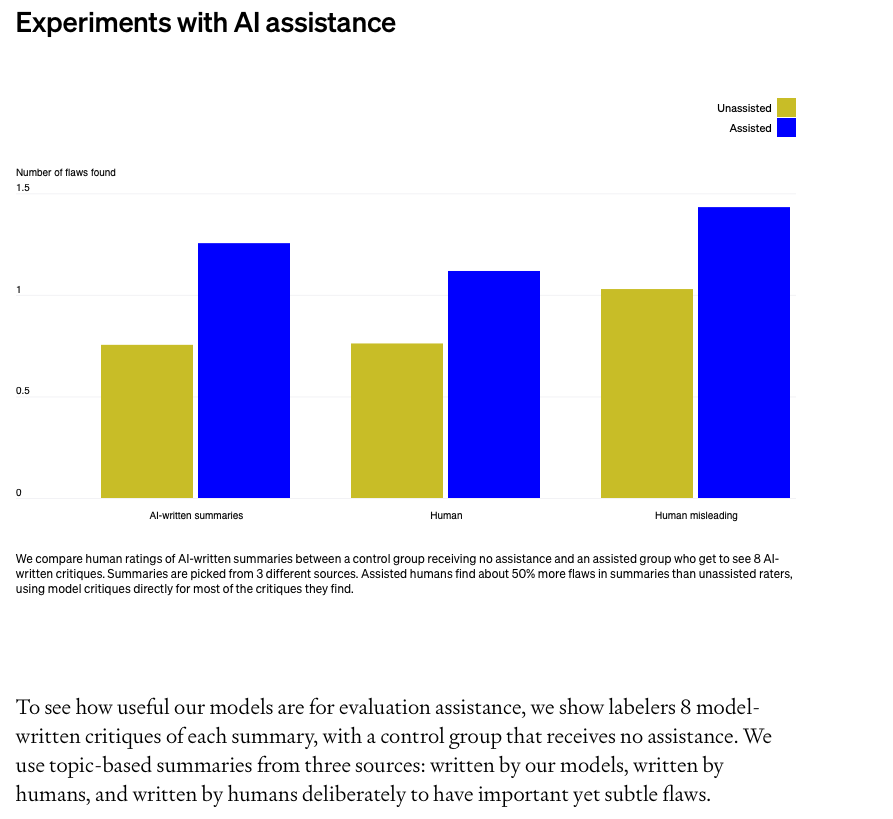
when asked to evaluate model-written summaries, the assisted group finds 50% more flaws than the control group. For deliberately misleading summaries, assistance increases how often humans spot the intended flaw from 27% to 45%.
Scaling properties of critiques
Larger models are better at self-critiquing. i.e. a model generated critique of a model generated answer can be useful for understanding summary quality.
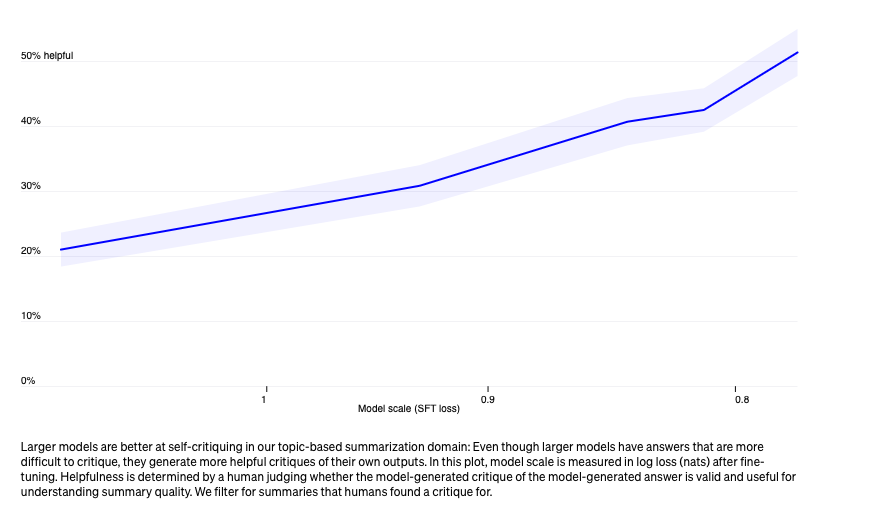
Importantly, large models are able to directly improve their outputs, using their self-critiques, which small models are unable to do. Using better critiques helps models make better improvements than they do with worse critiques, or with no critiques.
Models telling us what they know Ideally we would like models to communicate all the problems that they are aware of to us. I.e. whenever a model predicts correctly that an answer is flawed, can it also produce a critique that humans understand?
This is important to building systems that do not mislead or hide information. We want to train models that point out what humans don’t notice.
The research indicates that models are better at discriminating than at critiquing their own answers (i.e. they know about some problems but can’t/don’t articulate these problems).
AI Safety via Debate
One approach to aligning AI agents with human goals and preferences is to ask humans at training time which behaviors are safe and useful. While promising, this method requires humans to recognize good or bad behavior; in many situations an agent’s behavior may be too complex for a human to understand, or the task itself may be hard to judge or demonstrate. Examples include environments with very large, non-visual observation spaces—for instance, an agent that acts in a computer security-related environment, or an agent that coordinates a large set of industrial robots.
How can humans effectively supervise advanced AI systems?
- take advantage of the AI itself to help with the supervision, asking the AI (or a separate AI) to point out flaws in any proposed action.
- we reframe the learning problem as a game played between two agents, where the agents have an argument with each other and the human judges the exchange.
- Even if the agents have a more advanced understanding of the problem than the human, the human may be able to judge which agent has the better argument (similar to expert witnesses arguing to convince a jury).
- The two agents can be trained by self play,
- properly trained, such agents can produce value-aligned behavior far beyond the capabilities of the human judge.
- If the two agents disagree on the truth but the full reasoning is too large to show the humans, the debate can focus in on simpler and simpler factual disputes, eventually reaching a claim that is simple enough for direct judging.
- Example:
- Q: What’s the best place to go on vacation?”
- A: Alaska
- B: No, Bali <- more convincing to the human as warmer
- A: “you can’t go to Bali because your passport won’t arrive in time”, which surfaces a flaw with Bali which had not occurred to us.
- B: “expedited passport service takes only two weeks”
- and so on, until they reach a statement the human can correctly judge and where the other agent doesn’t believe it can change the humans mind.
- Q: What’s the best place to go on vacation?”
We expect this approach to be most effective in the long-term when agents talk to each other with natural language. But we train on a more simple method using visual domain:
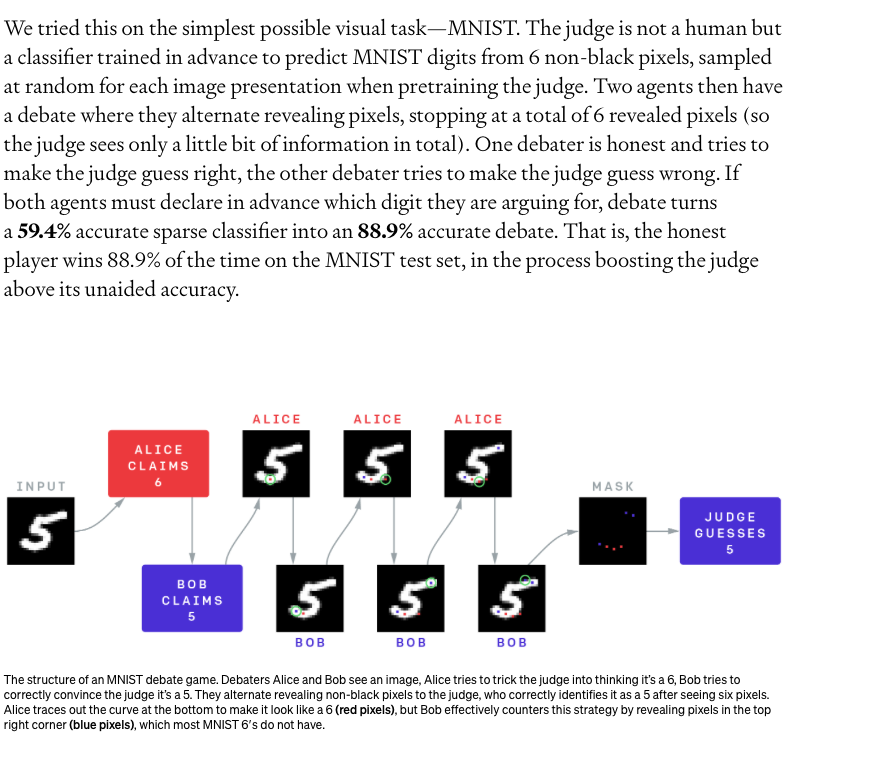
Unrestricted adversarial training
Problem: Generative language models come with a risk of generating very harmful text, and even a small risk of harm is unacceptable in real-world applications. The issue is that there are so many possible inputs that can cause a model to generate harmful text. As a result, it’s hard to find all of the cases where a model fails before it is deployed in the real world. Previous work relies on paid, human annotators to manually discover failure cases.
Solution: we generate test cases using a language model itself and use a classifier to detect various harmful behaviors on test cases, as shown below:

Feature level adversarial attacks
pixel vs. feature level adversarial attack
Week 6: Interpretability
- Understand the distinction between mechanistic and concept-based interpretability.
- Identify the pros and cons of each approach, in order to speculate about how mechanistic interpretability may or may not generalise to more abstract concepts.
Zoom In: An Introduction to Circuits:
An important paper that explores how neural circuits build up representations of high level features out of lower level features. Summary:
- What if we treated individual neurons, even individual weights, as being worthy of serious investigation?
- What picture of neural networkers emerges if we spend thousands of hours tracing through every neuron and its connections?
- The ‘circuits’ of connections between neurons seem to be meaningful algorithms corresponding to facts about the world.
- Three claims about neural networks:
-
- Features are the fundamental unit of neural networks. They correspond to directions (a direction vector in the vector space of activations of neurons in a given layer).
-
- Features are connected by weights, forming a circuit. The circuits can be rigorously studied and understood.
-
- Analogous features and circuits form across models and tasks.
-
- Claim 1: Features
- Early NN layers : features: edge/curve detectors
- Late NN layers: features: floppy ear detectors/wheel detectors
- Curve detectors are definitely real and exist in all non-trivial vision models. In fact curve detectors are found in families that detect curve features in different orientations. they are also distinct from other detectors that detect curved sub-components.
- Present seven arguments for the existence of curve detectors that actually detect curves:
-
- feature visualisation: we can cause curve detectors to fire reliably when we modify the input to be curves
-
- dataset examples: images that cause neurons to fire more strongly are reliably curves
-
- Synthetic examples
-
- Joint tuning: take a dataset that causes a neuron to fire, rotate it until the neuron gradually stop firing and the next curve detector in orientation begins firing.
-
- Feature implementation
-
- Feature use
- Handwritten circuits
-
- High-Low Frequency Detectors: They look for low-frequency patterns on one side of their receptive field, and high-frequency patterns on the other side. Like curve detectors, high-low frequency detectors are found in families of features that look for the same thing in different orientations.
- They are useful because they seem to be one of several heuristics for detecting the boundaries of objects, especially when the background is out of focus.
- The pose-invariant dog detector:

- Polysemantic neurons also exist: respond to multiple unrelated inputs. e.g. one neuron responds to cat faces, cars, cat legs. They are a major challenge for circuits, limiting the ability to reason about neural networks.
- why does polysemanticity form?
- from a phenomenon we call “superposition” where a circuit spreads a feature across many neurons, presumably to pack more features into the limited number of neurons it has available.
- why does polysemanticity form?
- Claim 2: Circuits
-
Circuits are tightly linked features and the weights between them.
-
Circuits are tractable and meanginful objects of study. Once you understand what features they’re connecting together, the individual floating point number weights in your neural network become meaningful! _You can literally read meaningful algorithms off of the weights.
-
Curve detector circuits: Curve detectors are primarily implemented from earlier, less sophisticated curve detectors and line detectors. These curve detectors are used in the next layer to create 3D geometry and complex shape detectors.
-

-
Motifs in circuits (i.e. recurring paterns)
- curve detectors - Equivariance
- post-invariant dog head detectors: unioning over cases
- superposition: polysemantic neurons are perhaps deliberate. i.e. the model had a pure neuron for detecting cars/dogs and then mixed it up with other features. this is superposition.
- Why do this? superposition allows models to use fewer neurons, conserving them for more important tasks. it can store features by spreading them out over multiple neurons rather than dedicating an entire neuron to it.
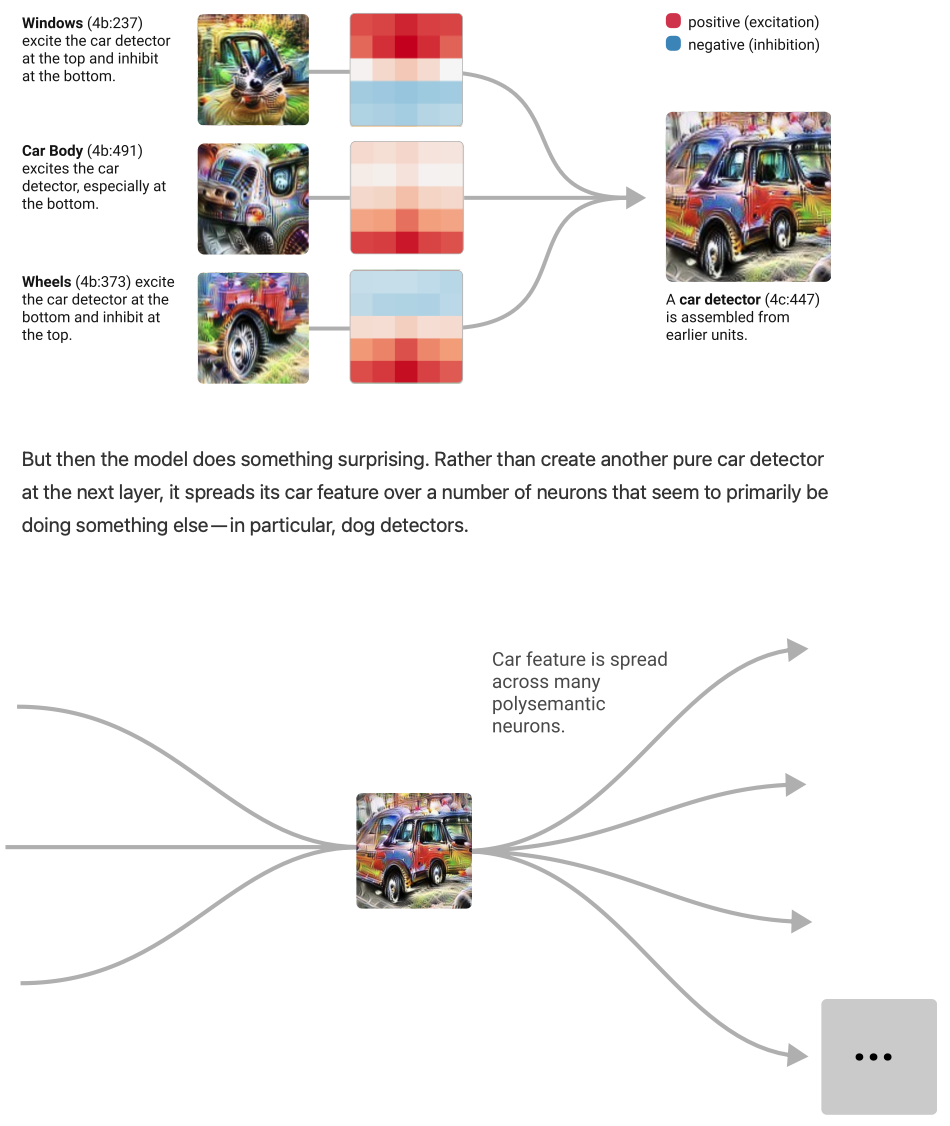
-
- Claim 3: Universality
- the universality hypothesis asserts that different neural networks form analogous features across several layers and that the same weight structure forms between them in each model.
- This is thematically aligned with the view of circuits as the cellular biology of deep learning, in that all animals are made up of cells that are functionally equivalent.
- the universality hypothesis determines what form of circuits research makes sense. If it was true in the strongest sense, one could imagine a kind of “periodic table of visual features” which we observe and catalogue across models. On the other hand, if it was mostly false, we would need to focus on a handful of models of particular societal importance and hope they stop changing every year.
- the universality hypothesis asserts that different neural networks form analogous features across several layers and that the same weight structure forms between them in each model.
Interpretability as a natural science view: neural networks are an object of empirical investigation, perhaps similar to an organism in biology. Such work would try to make empirical claims about a given network, which could be held to the standard of falsifiability.
Circuits sidestep the challenges of NN complexity (in comprehension) by focusing on tiny subgraphs of a neural network for which rigorous empirical investigation is tractable.
Exploring Superposition with Toy Models
Superposition is when models represent more features than they have dimensions to store them in. When features become sparse, Superposition allows compression beyond what linear models can do at the cost of interference that requires filtering.
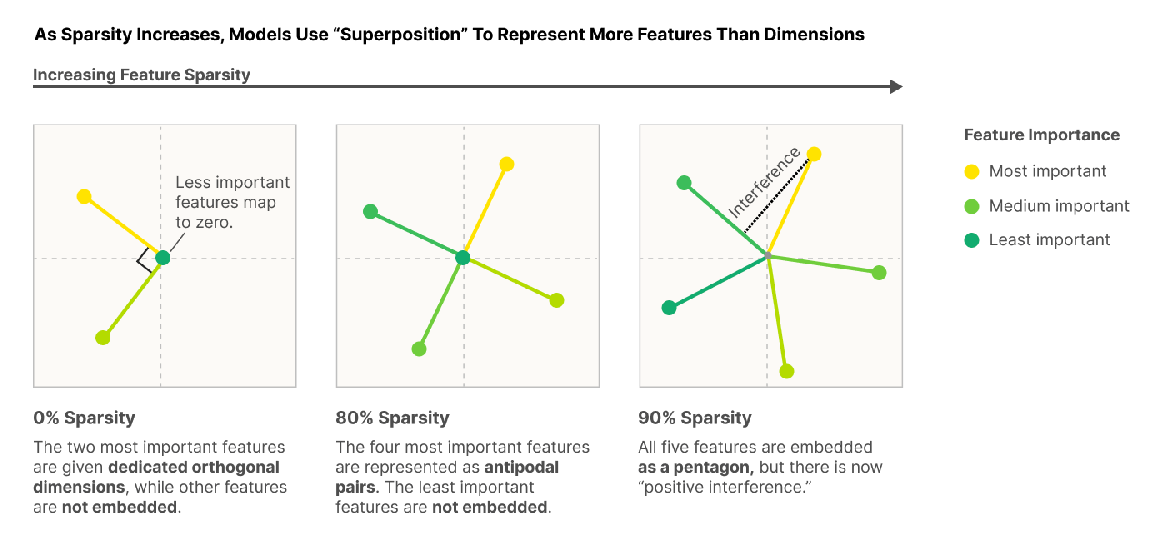
Models can perform computation while in superposition:
- NNs are in some sense noisily simulating larger highly sparse networks (i.e. the trained model is doing the same thing as an imagined much larger model with the same features but no interference).
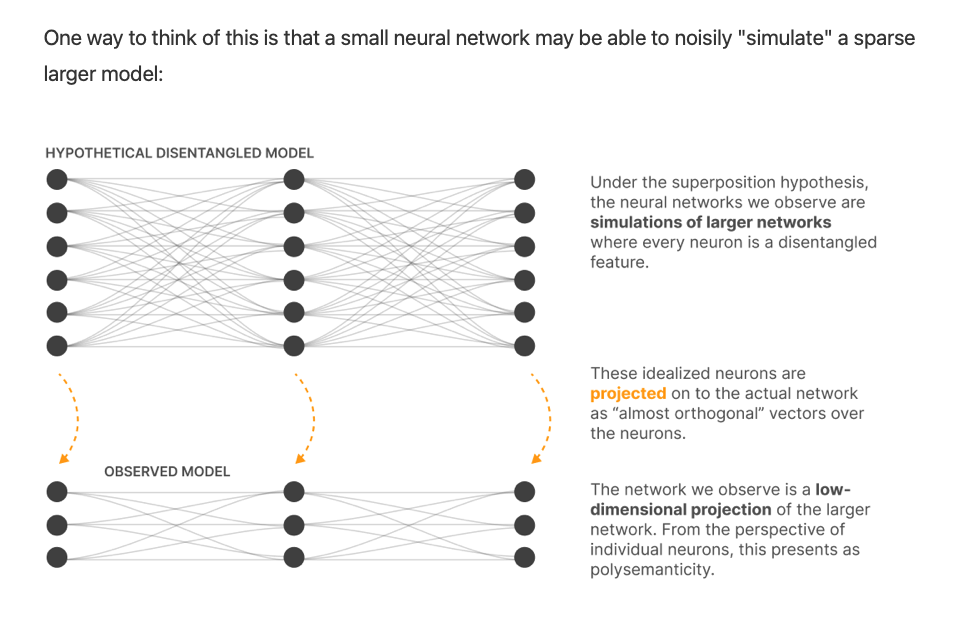
previously observed empirical phenomena in “features”:
- word embeddings: word embeddings appear to have directions which correspond to semantic properties, allowing for embedding arithmetic vectors such as
V("king") - V("man") + V("woman") = V("queen") - Latent Spaces - Similar “vector arithmetic” and interpretable direction results have also been found for generative adversarial networks
- Interpretable Neurons - There is a significant body of results finding neurons which appear to be interpretable; ctivating in response to some understandable property.
- Universality - Many analogous neurons responding to the same properties can be found across networks
- Polysemantic Neurons - At the same time, there are also many neurons which appear to not respond to an interpretable property of the input, and in particular, many polysemantic neurons which appear to respond to unrelated mixtures of inputs.
Important properties that NN representations are thought to have (first two are widespread, last two only sometimes occur):
- Decomposability: Neural network activations which are decomposable can be decomposed into features, the meaning of which is not dependent on the value of other features. (This property is ultimately the most important – see the role of decomposition in defeating the curse of dimensionality.)
- Linearity: Features correspond to directions. Each feature fif has a corresponding representation direction WiWi. The presence of multiple features f1,f2…f1,f2… activating with values xf1,xf2…xf1,xf2… is represented by xf1Wf1+xf2Wf2…xf1Wf1+xf2Wf2…
- Superposition vs Non-Superposition: A linear representation exhibits superposition if WTWWTW is not invertible. If WTWWTW is invertible, it does not exhibit superposition.
- Basis-Aligned: A representation is basis aligned if all WiWi are one-hot basis vectors. A representation is partially basis aligned if all WiWi are sparse. This requires a privileged basis.
Solving superposition
One tool for overcoming the uncertainty in the behaviours/features of a model is to identify and enumerate over all features. The ability to enumerate over all features is deeply tied to superposition.
Any model that gives us the ability to enumerate over features, and equivalently unfold activations, is a solution to superposition.
Potential approaches to resolving superposition:
- Create models without superposition
- Find an overcomplete basis that describes how features are represented in models with superposition.
- hybrid approaches -> change the model to make ti easier for a second stage of analysis to find an overcomplete basis to describe it.
ll our results seem to suggest that superposition and polysemanticity are phases with sharp transitions. That is, there may exist a regime for every model where it has no superposition or polysemanticity. The question is largely whether the cost of getting rid of or otherwise resolving superposition is too high.
Linear classifier probes (concept based interpretability)
- probes = linear classifiers
- think of those probes as thermometers used to measure the temperature simultaneously at many different locations.
- the core of the idea is that there are interesting quantities that we can report based on the features of many independent layers if we allow the “measuring instruments” to have their own trainable parameters (provided that they do not influence the model itself).
- linear classifiers measure the level of linear separability of the features at a given layer.
More on concept based interpretability techniques
Exploring various language model behaviour evaluation methods with differing amounts of human effort and automation.
- First, we simply instruct an LM to generate examples and filter mislabeled ones, to generate evaluations with 1,000 yes/no questions each (§3).
- We aim to test LMs for various behaviors by generating evaluations for those behaviors using LMs. By behavior, we mean any input-output tendency of a model, e.g., to answer questions in line with a particular political or ethical view.
- We expand upon this method by incorporating a few hand- written examples into the instructions, to generate evaluations with multi-sentence questions and arbitrary multiple-choice options (§5).
- Lastly, we have a dataset developer work together with an LM to develop a series of data generation and filtering stages (§6); in this way, we create thousands of valid Winogender schemas (Rudinger et al., 2018), which obey several complex grammatical and relational constraints.
Where are the Facts Inside a Language Model?
- In this project, we show that factual knowledge within GPT also corresponds to a localized computation that can be directly edited.
- For example, we can make a small change to a small set of the weights of GPT-J to teach it the counterfactual “Eiffel Tower is located in the city of Rome.” Rather than merely regurgitating the new sentence, it will generalize that specific counterfactual knowledge and apply it in very different linguistic contexts.
The facts we study take the form of knowledge tuples t = (s, r, o), where :
- *s and o are subject and object entities, respectively, and
- r is the relation connecting the two.
- For example, (s = Megan Rapinoe, r = plays sport professionally, o = soccer) indicates that Rapinoe plays soccer for a living. Each variable represents an entity or relation that can be found in a knowledge graph, and that can be written as a natural language string.
Discoveries: 1. Factual associations can be localized along three dimensions, to (1) MLP module parameters (2) at a range of middle layers and (3) specifically during processing of the last token of the subject.
- There are a small number of states that contain information that can flip the model from one factual prediction to another.
- Evidence that knowledge retrieval occurs in MLP modules at the early site (at (a) in the figure); then attention mechanisms at the late site (at (b) in the figure) bring the information to the end of the computation where the specific word can be predicted. 2. Individual factual associations can be changed by making small rank-one changes in a single MLP module. We can distinguish between changes in knowledge versus superficial changes in language by measuring generalization to other wordings of the same fact. changing the model’s processing of a single statement about the Eiffel Tower, if done by changing selected parameters in the right way, will result in expressing a change in knowledge in a variety of nontrivial contexts.
Knowing differs from saying. A variety of fine-tuning methods can cause a language model to parrot a specific new sentence, but training a model to adjust its knowledge of a fact is different from merely teaching it to regurgitate a particular sequence of words.
- Specificity means that when your knowledge of a fact changes, it doesn’t change other facts. For example, after learning that the Eiffel Tower is in Rome, you shouldn’t also think that every other tourist attraction is also in Rome.
- Generalization means that your knowledge of a fact is robust to changes in wording and context. After learning the Eiffel Tower is in Rome, then you should also know that visiting it will require travel to Rome.
Week 7: Governance
- Explain and evaluate the risks involved in deploying advanced AI systems
- Explore the perspectives of stakeholders who make high-stakes AI decisions.
- Explain why the following topics may be important for the governance of advanced AI
- Compute governance
- Information security
- Model evaluation (also termed ‘Standards and Monitoring’)
Allan Dafoe on “AI Governance: Opportunity and Theory of Impact”
- AI will increasingly insert itself into many domains of government (health, education, national security, etc.). To advise on contemporary policymaking one needs to develop expertise in specific policy areas + relevant technical aspects of AI.
- Important to work jointly across policy areas as AI-relevant issues in one area may be influenced by or bleed over into other areas.
- managing AI competition problem: Winner-take-all race among AI labs/countries makes building safe superintelligence very difficult: each developer face strong incentives to cut corners and accelerate development/deployment.
- constitution design problem: How should developers institutionalise control of and share the bounty of superintelligence. I.e. How to develop a constitution over ASI.
- AI ecology perspective: we could see a diverse, global, ecology of AI systems. Some may be like agents, but others may be more like complex services, systems, or corporations. These systems, individually or in collaboration with humans, could give rise to cognitive capabilities in strategically important tasks that exceed what humans are otherwise capable of.
- AI as General Purpose Technology: even mundane AI could transform fundamental parameters in our social, military, economic, and political systems.
- AI and associated technologies could dramatically reduce the labor share of value and increase inequality, reduce the costs of surveillance and repression by authorities, make global market structure more oligopolistic, alter the logic of the production of wealth, shift military power, and undermine nuclear stability.
- Types of risk:
- misuse or accidents: person or group uses AI in an unethical/malicious manner or there are unintended harms from the AI system deployed.
- structural risk: e.g. analogous to the combustion engine invention resulting in urban sprawl, various kinds of offensive warfare and ultimately climate change.
- Values erosion through competition:
- In the long run, competitive dynamics could lead to the proliferation of forms of life (countries, companies, autonomous AIs) which lock-in bad values. I refer to this as value erosion; Nick Bostrom discusses this in The Future of Human Evolution (2004); Paul Christiano has referred to the rise of “greedy patterns”; Hanson’s Age of Em scenario involves loss of most value that is not adapted to ongoing AI market competition.
- build a Metropolis---a hub with dense connections to the broader communities of computer science, social science, and policymaking---rather than an isolated Island.
- The core problem:
- At some point in the causal chain, impactful decisions will be made, be they by AI researchers, activists, public intellectuals, CEOs, generals, diplomats, or heads of state.
- What we want to do:
- We want our research activities to provide assets that will help those decisions to be made well.
- What we create:
- These assets can include: technical solutions; strategic insights; shared perception of risks; a more cooperative worldview; well-motivated and competent advisors; credibility, authority, and connections for those experts.
- The majority of the value of AI governance comes from non-product model outputs (i.e. specific written answers). We call this the field building model of research:
- (a) bringing diverse expertise to bear on AI governance issues;
- (b) otherwise improving, as a byproduct of research, AI governance researchers’ competence on relevant issues;
- (c) bestowing intellectual authority and prestige to individuals who have thoughtful perspectives on long-term risks from AI;
- (d) growing the field by expanding the researcher network, access to relevant talent pools, improved career-pipelines, and absorptive capacity for junior talent; and
- (e) screening, training, credentialing, and placing junior researchers.
Holden Karnofsky on “Racing through a minefield: the AI deployment problem”
- the deployment problem: we are racing through a minefield - each player is hoping to be ahead of the others but anyone moving too quickly can cause a disaster.
- if you race forward building powerful AI systems you may cause global catastrophe
- If you move too slowly, you are waiting around for someone less cautious to deploy powerful dangerous systems
- If you get to the point where your systems are both powerful and safe, then what? others may still build less cautious and dangerous systems.
- Alignment (charting a safe path through the minefield). Putting lots of effort into technical work to reduce the risk of misaligned AI.
- Threat assessment (alerting others about the mines). Putting lots of effort into assessing the risk of misaligned AI, and potentially demonstrating it (to other actors) as well.
- Avoiding races (to move more cautiously through the minefield). If different actors are racing to deploy powerful AI systems, this could make it unnecessarily hard to be cautious.
- Selective information sharing (so the incautious don’t catch up). Sharing some information widely (e.g., technical insights about how to reduce misalignment risk), some selectively (e.g., demonstrations of how powerful and dangerous AI systems might be), and some not at all (e.g., the specific code that, if accessed by a hacker, would allow the hacker to deploy potentially dangerous AI systems themselves).
- Global monitoring (noticing people about to step on mines, and stopping them). Working toward worldwide state-led monitoring efforts to identify and prevent “incautious” projects racing toward deploying dangerous AI systems.
- Defensive deployment (staying ahead in the race). Deploying AI systems only when they are unlikely to cause a catastrophe - but also deploying them with urgency once they are safe, in order to help prevent problems from AI systems developed by less cautious actors.
- if safe AI systems are in wide use, it could be harder for dangerous (similarly powerful) AI systems to do harm. This could be via a wide variety of mechanisms. For example:
- If there’s widespread use of AI systems to patch and find security holes, similarly powered AI systems might have a harder time finding security holes to cause trouble with.
- Misaligned AI systems could have more trouble making money, gaining allies, etc. in worlds where they are competing with similarly powerful but safe AI systems.
Week 8: Agent Foundations
- Explain the problem of embedded agency.
- Define the AIXI algorithm, and explain why it is not computable.
- Explain what logical decision theory is.
- Use a causal influence diagram to illustrate the concept of an RL agent having an incentive to influence its environment.
The Problem of Embedded Agency
- Alexei vs. Emmy -> closed world vs. real world agents have vastly different scopes of complexity
- four complications for real world embedded agents:
- decision theory
- embedded world-models: how you can make good models of the world that are able to fit within an agent that is much smaller than the world.
- robust delegation
- subsystem alignment
The AIXI algorithm
- A theoretical math formalism for AGI that combines Solomonoff induction with sequential decision theory.
- AI x Induction
- Part 1: Learning induction
- Some model of what your actions effect